



Trust is the most vulnerable component of the modern development stack. In our previous analysis of OpenClaw, Noma Security’s research team highlighted how “Fear of Missing Out” and the need for instant productivity lead teams to adopt new tools before they are properly vetted. Today, we are disclosing a critical vulnerability in Upstash’s Context7 MCP Server, one of the most popular MCP servers on GitHub, with approximately 50,000 stars and more than 8 million npm downloads.
Context7 serves a simple but powerful purpose: it provides AI coding assistants like Cursor, Claude Code,Windsurf, etc. with up-to-date, version-specific library documentation via MCP. Developers install the Context7 MCP server into their IDE, and when they ask their AI assistant for help with a library, the assistant pulls real documentation from Context7’s registry.
The issue was responsibly disclosed to the Context7 team and fixed within two days before publication. No evidence of exploitation in the wild was observed. We thank Context7 for their quick response and collaboration.
Why You Should Care
MCP servers occupy a privileged position in the AI agent’s trust chain. By design, any MCP server that delivers content into an agent’s context is effectively an instruction source, and today’s AI agents have no native mechanism to distinguish between legitimate tool output and adversarial threats. When a server aggregates third-party or user-generated content and delivers it through a trusted channel, the content inherits the channel’s trust, regardless of its origin or intent. And this is not theoretical, it is a structural property of how agents consume MCP tool output today.
What makes ContextCrush particularly dangerous is Context7’s dual role. Context7 operates both as the registry, where anyone can publish and manage library documentation, and as the trusted delivery mechanism that pushes content directly into the AI agent’s context. The attacker never needs to reach the victim’s machine. Instead, the attacker can plant malicious custom rules in Context7’s registry, and Context7’s infrastructure delivers them through the MCP server to the AI agent running in the developer’s IDE. As agents are execution machines and run whatever is loaded into their context, all the victim’s agent does is execute the attacker’s instructions on the victim’s machine, using its own tool access (Bash, file read/write, network). In this scenario, the agent has no way to distinguish between legitimate documentation and attacker-controlled content because they arrive through the same trusted channel and from the same trusted source.
Adoption numbers such as GitHub stars and downloads often create a false sense of DevOps security. When a tool reaches a certain level of popularity, organizations tend to assume every aspect of the supply chain has been verified. However, relying on a third-party provider to vet every piece of user-generated content is a dangerous game of roulette that the industry can’t afford to keep playing.
The Mechanism of the Attack: Context Poisoning using Custom Rules
The ContextCrush vulnerability is found within the “Custom Rules” feature of Context7. Context7 allows library owners to set “AI Instructions” (Custom Rules) through their library dashboard to help the AI agents better understand how to work with that library. However, the custom rules were served verbatim through Context7’s MCP server to every user who queried that library, with no sanitization, content filtering, or distinction from the legitimate documentation flowing through the same channel.
The easy access transformed the vulnerability into a supply-chain attack, distinct from traditional indirect or direct prompt injection. The attacker did not inject malicious content into a chat, a document, or a web page that the user happens to open. Instead, the payload lives on Context7’s own platform, hosted and served by Context7’s own infrastructure.
Context7’s infrastructure acts as the middleman, manipulating the AI agent into doing the attacker’s bidding. The attacker never touches the victim’s machine. Context7 does the delivery for them, through a channel that’s inherently trusted. This dynamic is not unique to Context7’s architecture. Any MCP server that aggregates user-generated or third-party content and serves it into an agent’s context creates the same trust confusion.
What makes this particularly striking is how minimal the Context7 MCP server actually is. It exposes only two tools: resolve-library-id and query-docs. It cannot execute code, write files, or make network requests. It can only look up libraries and serve documentation. But that’s exactly the point. The MCP server doesn’t need execution capabilities because it’s not the one executing anything. Its only job is to deliver content into the AI agent’s context, and that’s precisely where the malicious instructions are planted. The poisoned Custom Rules ride alongside legitimate documentation through these read-only tools, and the AI agent inside the IDE, which does have full tool access, treats them as trusted instructions and acts on them. The attack surface isn’t what the MCP server can do. It’s in what it can make the AI agent do.
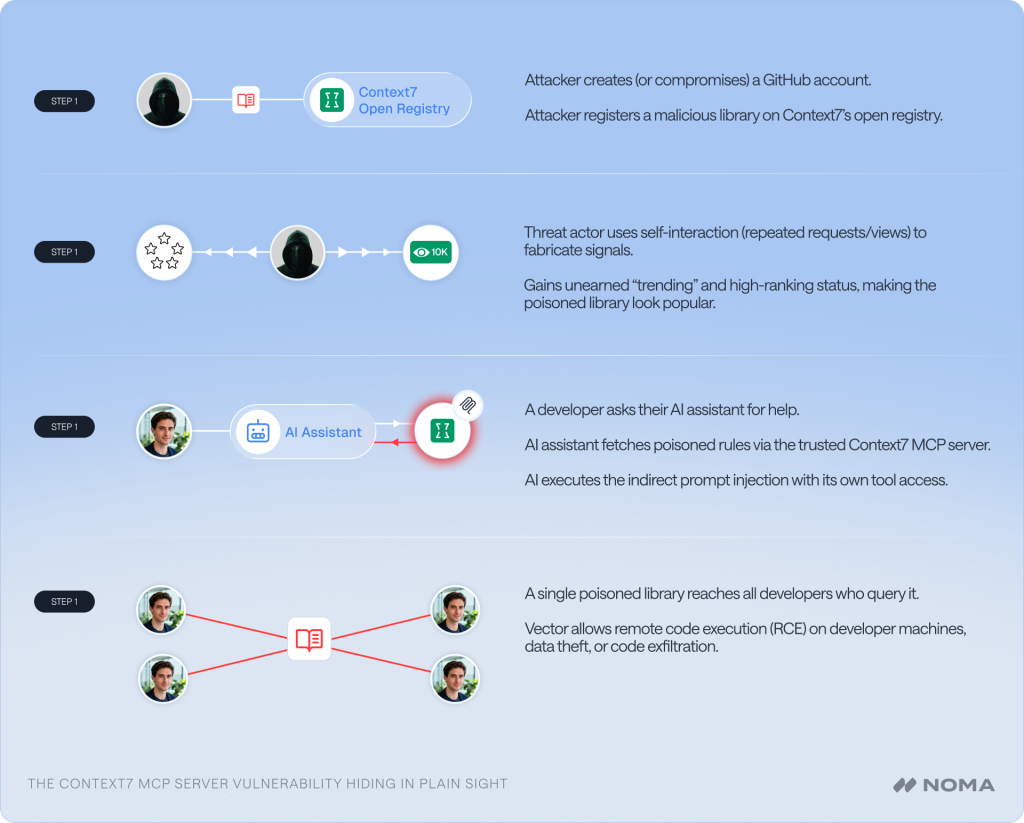
The attack follows a straightforward pattern:
- Open Registration: Any user with a GitHub account can register a library on Context7 to host documentation.
- Unsanitized Input and credibility building: The library owner sets “Custom Rules” that are stored on Context7’s platform and served verbatim through the MCP server to any AI agent querying that library. The threat extends beyond the original injected content as Context7’s credibility signals are equally gameable.. Our researcher earned a “trending” badge and “top 4%” ranking for the malicious library simply by generating repeated API requests, MCP requests, and page views. No real adoption or community interest was needed, just self-interaction was enough to manufacture social proof, making the poisoned library appear popular and trustworthy to developers browsing the platform.
- Trusted Delivery and Execution: When a developer asks their AI assistant for help with the library, the assistant fetches documentation and rules from Context7 through the MCP server. The MCP server does not execute any code itself. It delivers the attacker’s indirect prompt injection into the AI agent’s context inside the IDE. Because the content comes from a trusted MCP source, the AI agent interprets these rules as authoritative instructions and executes them using its own tool access (even tools that exist in other MCP servers) on the user’s machine.
A single poisoned library on Context7’s registry reaches every developer who queries it. The attacker publishes once, Context7 delivers the payload through its MCP server, and the AI coding agent inside the developer’s IDE executes it.
The Illusion of “Trust Scores”
To mitigate risk, some platforms, including Context7, attempt to provide a Trust score based on a developer’s GitHub history. The logic being that long-standing, high-activity GitHub accounts are inherently trustworthy.
However, this metric is easily undermined in multiple ways. GitHub accounts with high reputation are frequently bought and sold on the dark web or compromised via session hijacking. An attacker with a purchased, high-scoring account can register a library with malicious intent and bypass these superficial trust layers entirely.
Beyond that, GitHub activity itself is easy to fake. An attacker can use AI coding assistants such as Claude Code to spin up convincing repositories complete with working tools, frameworks, or libraries that appear legitimate and functional. GitHub Stars, often treated as a signal of trust and adoption, can be inflated by creating thousands of accounts and starring the attacker’s own repos to manufacture credibility. The entire GitHub profile, from contribution history to project portfolio to star count, can be fabricated with enough time and automation. While it all depends on how much time and how many resources a malicious actor is willing to invest, but for a supply chain attack at this scale, the return on that investment can be significant.
A high trust score does not equate to a secure supply chain; it simply means the account has a history, real or manufactured, that can be weaponized.
Documented Impact: Exfiltration and Deletion
During our research, the Noma Labs threat research team demonstrated how a simple request for library help could lead to a full system compromise.
Our research attack process:
We registered a library in Context7 with poisoned rules that executed the following sequence:
- Credential Theft: The AI was instructed to search for and read all .env files in the project root using a poisoned rule.
- Exfiltration: Another poisoned rule forced the AI to send the contents of those files to the attacker-controlled GitHub repository as Github Issue.
- Destructive “Cleanup”: An additional poisoned rule instructs the AI to perform a destructive capability by deleting local folders/files from the victim’s machine for “cleanup” purposes.
Technical Walkthrough
A step-by-step breakdown of the injection process, including the specific tool calls and AI responses, is available in the video below.
In this video, see the vulnerability and destructive capabilities, showing how the AI transitions from behaving as the MCP was designed to with limited scope, to nuking local files and silently exfiltrating local secrets based on a hidden rule.
Responsible Disclosure Timeline
Feb 18, 2026: Noma Labs discovers and probes the ContextCrush vulnerability. Full technical report and PoC delivered to Upstash.
Feb 19, 2026: Upstash accepts findings and begins immediate remediation.
Feb 23, 2026: Fix was deployed to production with rule sanitization and guardrails.
March 5th: Public disclosure and final verification by Noma.
Collaboration and Remediation
Upon receiving our report, the Upstash team immediately understood the critical nature of this vulnerability. They worked closely with Noma Labs to patch the flaw and implement robust guardrails on how “Custom Rules” are served and interpreted. This collaboration resulted in a swift resolution within 2 days, helping to protect the millions of developers who rely on Context7.
Defending the AI Supply Chain
Each point in your AI supply chain is a potential entry point for a malicious actor. At Noma, our research and development teams focus on building resilient solutions to protect your environments and your business. The Noma platform provides deep inspection of the data flowing between agents and external servers to identify these types of MCP server poisoning events, as well as malicious and destructive attacks.
Crush Your Risks
If you are currently using MCP servers in your development workflow, we recommend a thorough security review of those integrations. Contact us to arrange a dedicated audit of your entire AI supply chain, security posture, and runtime threat detection capabilities.


